
Polarith AI



1.8
Here, the decision making pipeline is explained in detail and it is summarized how the components of Polarith AI work together.
Let's start right away. The complete pipeline and data flow for making a decision is as follows, whereby the following sections provide details for each of these steps.
The following Figure 1 shows the initial situation, an agent (blue), its sensor having a receptor count of 8 and a perceived object (green). The agent must fulfill two conditions in order to initiate the decision making process:
For now, let's assume that the agent meets both conditions and an attached Seek behaviour is referencing to the green circle.
Now that our agent perceives at least one object (percept), let's have a look at how values are written (in the next section).
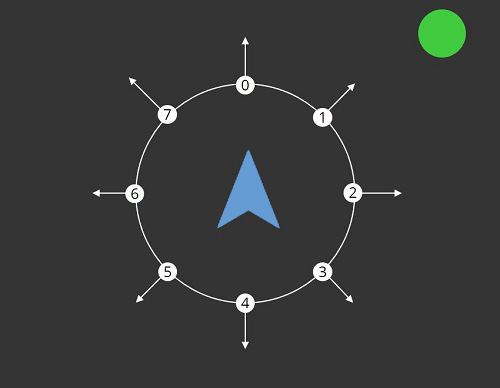
Figure 1: Shows an agent (blue) and an perceived interesting object (green). The white circle around the agent is an illustration of the agent's sensor which has a receptor count of eight.
Steering behaviours repeat the following algorithm in every update (or in a fixed number of updates depending on your set UpdateFrequncy settings).
If there is just one Seek with default parametrization, the result would look like in Figure 2. Since the default receptor Sensitivity is 90°, only receptors having an angle smaller than 90° would recognize the object. Depending on many factors, like the receptor's magnitude multiplier, the distance mapping and the set value mapping, a value is written into the corresponding objective like in Figure 2. All scalar factors are described on the steering behaviour page.
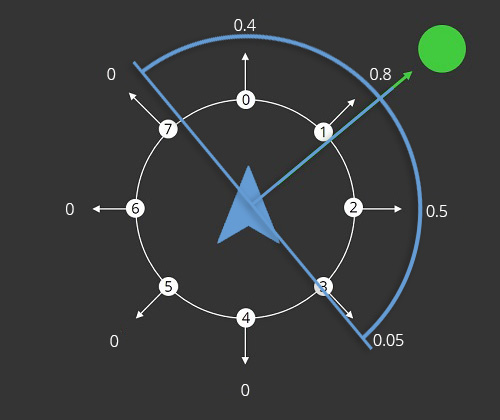
Figure 2: Shows the objective values of the first and, in this case, only objective. The blue circular illustration should indicate the sensitivity.
After this step, we have sampled a very simple discrete optimization problem. It is very easy to solve because we just need to find the smallest or greatest value (in this case the greatest value). However, like in the real world, our agent has most likely more than one objective which must be optimized at the same time. Actually, it wants to maximize its interest.
If we introduce a second object which represents some kind of danger, e.g. an obstacle which should be avoided, we need a second objective: Danger. Of course, we want to minimize this so that the agent avoids solutions towards dangerous directions. The result of such a setup can be seen in Figure 3.
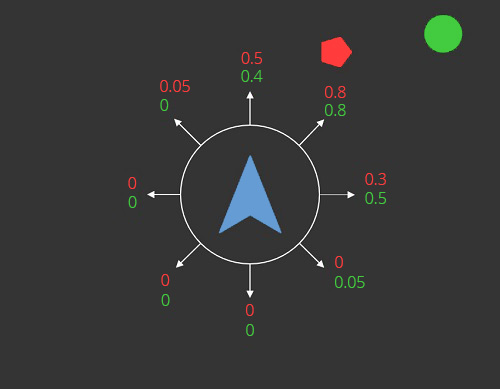
Figure 3: Depicts the objective values for both the interest (green) and danger (red) objective.
After all active behaviours were executed, in this case, the two Seek steering behaviours, we have sampled a so called multi-criteria optimization (MCO) problem. As we can see in Figure 3, there is no clear best solution anymore because the two objectives are in conflict. If we would only maximize the interest and take the solution (0.8, 0.8) we would have also maximized the danger that we want to minimize.
To solve this problem, our system utilizes an inbuilt MCO solver, the ConstraintSolver. This solver is suitable for an objective count up to 5. It also works for greater objective counts, however, it is mathematically proven that the precision for finding a proper solution drops dramatically when increasing the objective count any further.
When solving an MCO problem for n objectives, there are n - 1 objectives which needs to have a constraint. The field Unlimited in the Context determines which objective is the main objective with no constraint. The solver then optimizes according to these set constraints. Thus, every possible solution which violates a constraint is rejected, like in Figure 4. Here, the constraint for the danger objective was set to 0.6. Thus, the solution (0.8, 0.8) is rejected. A constraint is violated if and only if:
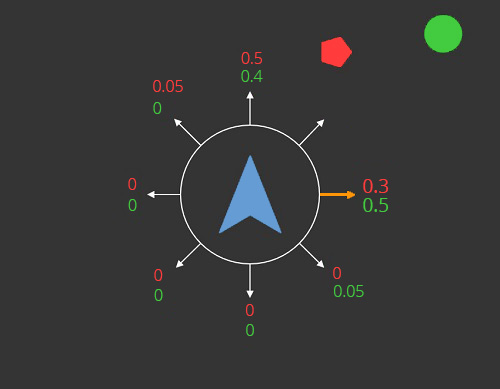
Figure 4: The receptor facing directly towards the danger is rejected because it violates the constraint of the danger objective. The remaining possible solutions are shown and the receptor to the right is chosen because it has got the best interest value.
The decision which is selected by the MCO solver corresponds to one of the receptors. Although it is possible to increase the receptor count, the result always remain a discrete decision in a continuous world. The consequence can be seen in Figure 2 above, it is not possible for the system to chose a receptor which points directly to the target.
However, this issue can be resolved by attaching an interpolation behaviour. Currently, only one interpolation behaviour is available, the Planar Interpolation behaviour. It takes an already made decision and computes a possible better solution in between the discrete receptors based on the neighbourhood of the found solution.
The result of the overall (movement) AI pipeline is a decision. In general, this decision includes the following basic information.
DecidedDirection, like the name suggests, this is the best (possibly interpolated) direction which can be found.DecidedValues, the (possibly interpolated) objective values corresponding to the DecidedDirection.Besides these major data, there are other information belonging to a Decision as well. Therefore, have a closer look at the corresponding API reference.
Now, we have got a decision, an appropriate character controller has the task to interpret these data and to transform it into movement. For example, the DecidedDirection can be used as the direction for the next movement step, whereby the DecidedValues might be used to scale the velocity of the agent.
What you do with these values the AI systems provides depends on your specific application. Due to the fact that we cannot foresee how your application or game works in detail, it is up to you to write a controller which fits your scenario best. Do not be afraid to contact us when you need help for translating AI decisions into proper controller movement. We help you as best as we can.